

“Space for Sustainable Development” by ESA
Space for Sustainable Development
Speaker: Pierre-Philippe Mathieu — ESA
The view from space has forever changed our vision on our home planet, revealing its beauty while pointing at the same time to its inherent fragility. This new perspective from above contributed to the emergence of the concept of Sustainable Development (SD), by convincing many of the need to (better) manage our (rapidly depleting) resources in a sustainable manner that would “meet the needs of the present without compromising the ability of future generations to meet their own needs”.
Over the last decades, the principles of SD were progressively adopted by world leaders on the occasion of a series of Earth Summits. One of the key challenges to implement SD however lies in one’s ability to measure it. As stated by Lord Kelvin, “if you cannot measure it, you cannot improve it”. The challenge is further compounded by the inherent global nature of the problem, which calls for global data sets.
Earth Observation (EO) satellites can play a key role to meet this challenge, as they uniquely placed to monitor the state of our environment, in a global and consistent manner, ensuring sufficient resolution to capture the footprint of man-made activities.
The world of EO is rapidly changing driven by very fast advances in sensor and digital technologies. The speed of change has no historical precedent. Recent decades have witnessed extraordinary developments in ICT, including the Internet and cloud computing, and technologies such as Artificial Intelligence (AI), leading to radically new ways to collect, distribute and analyze data about our planet. This digital revolution is also accompanied by a sensing revolution providing an unprecedented amount of data on the state of our planet and its changes.
Europe is leading this sensing revolution in space through the EO missions of the European Space Agency (ESA), a new generation of meteo missions for Eumetsat, and especially the Copernicus initiative led by the European Union (EU). The latter is centered around the development of a family of Sentinel missions by ESA for the EU so as to enable global monitoring of our planet on an operational and sustained basis over the coming decades. In addition, a new trend, referred to as “New Space” in the US or “Space 4.0” in Europe, is now rapidly emerging through the increasing commoditization and commercialization of space. In particular, with the rapidly dropping costs of small sat building, launching and data processing, new EO actors including startups and ICT giants, in particular across the Atlantic, are now massively entering the space business, resulting in new constellations of small-sats delivering a new class of data on our planet with high spatial resolution and increased temporal frequency.
These new global data sets derived from space lead to a far more comprehensive picture of our planet, thereby enabling the monitoring of SD progress. In this context, this talk will briefly present some elements of the ESA EO programs and missions, and their evolution, highlighting their related scientific and societal applications, in particular regarding how space can help in supporting SD.
#ESA #EarthObservation #space #sustainability #development


“Brainstorming on what Artificial Intelligence is and how to master it” by Vastalla
Artificial Intelligence is everywhere: brainstorming on what AI is and how to master it
Speaker: Stefano T. Chiadò — Vastalla
Artificial Intelligence is everywhere. Almost every startup doing financing rounds claims to be built on strong AI foundations.
But is it really so? Do we all agree on what Artificial Intelligence is? What is the state of the art in AI? What is its supposed long term evolution?
During the talk we will explore if you are a Padawan, a Knight or a Master in practicing AI. We will also brainstorm about the importance to gain the level required for the desired results. We will talk about efficiency and the importance of not reinventing the wheel making use of what is available on the market (i.e. AWS tools, Google code, etc.)
Prerequisites: common sense and open mind.
#AI #ML #brainstorming #AWS
“Data Visualization with D3.js” by TODO
Data Visualization with D3.js
Teacher: Fabio Franchino — TODO
Immersive lecture on the key elements and concepts behind data visualization.
The workshop is an immersive tutorial about how to use the JavaScript open source library D3.js to represent data and to create customized and animated diagrams and charts.
Prerequisites: HTML, CSS, previous experience with JavaScript is welcome.
#dataviz #datavisualization #d3js #javascript


“Crash course in Python and data science libraries” by TOP-IX
Crash course in Python and data science libraries
Teacher: Stefania Delprete — TOP-IX
Interactive lessons using Jupyter Notebooks on Python and its most used libraries for data science: NumPy, Pandas, Matplotlib, and an initial Scikit-learn exposure. Plus you’ll get clear on what’s inside the Anaconda and SciPy ecosystems.
This session will include insights of the history and future of the open source libraries, how to contribute and participate to the community events.
Stickers from the students provided by Python Software Foundation and NumFOCUS.
Prerequisites: Exposure to Python and Jupyter Notebooks.
#datascience #python #numpy #pandas #matplotlib #seaborn
“Spatial is special: geo technologies and data” by FBK
From local to global using community data
Teacher: Maurizio Napolitano — Fondazione Bruno Kessler
The workshop is an introduction to the geospatial technologies and everything needed to create maps and analyze geographical data.
As data sources will be used several open data sources including OpenStreetMap.
Prerequisites: Python and a complete installation of QGIS 3.6+
#geospatial #map #opendata #osm #qgis #geopandas


“Data Analysis with Spark Streaming” by Agile Lab
Data Analysis with Spark Streaming
Teacher: Nicolò Bidotti — AgileLab
Big Data analysis is a hot trend and one of its major roles is to give new value to enterprise data. However data and information lose value as they become old, so it is important in a lot of contexts to do near real-time analysis of incoming data flows. Apache Spark is a major actor in the big data scenario and with its Streaming module aims to solve the main challenges in real-time data processing at scale in distributed environments.
This session aims to show the potential of streaming data analysis and how to leverage on Apache Spark with Structured Streaming to extract value from it without taking care of common problems of streaming processing at scale already solved by Apache Spark.
Prerequisites: Python.
#bigdata #dataengineering #dataframework #apachespark


“Understanding NLP universe and the I-REACT project” by CELI
Understanding NLP universe and the I-REACT project
Teacher: Francesco Tarasconi — CELI
NLP lecture on the relations between Artificial Intelligence, Machine Learning and the mission of understanding natural language. Unstructured data as a potential asset, but also as a great challenge. Success in reaching state-of-the-art performance does not automatically translate into success in real-world problems. Overview of distributional methods and word embedding. Recent trends and breakthroughs in language modeling, with a focus on its practical applications.
Case study: I-REACT – Improving Resilience to Emergencies through Advanced Cyber Technologies.
I-REACT is an innovation project funded by the European Commission. The proposed system targets public administration authorities, private companies, as well as citizens in order to provide increased resilience to natural disasters, effective and fast emergency response, increased awareness and citizen engagement.
CELI leads two specific tasks: “Linked Data and Semantic structure” and “Social Media Data Engine”.
Prerequisites: Python
#datascience #NLP #python #pytorch


“AWS for data – from development to production” by ThoughtWorks
AWS for data – from development to production
Teacher: Alex Comunian — ThoughtWorks
The aim of the module is to provide a brief introduction on Amazon Web Services concerning Data management.
The teacher will provide an overview on the main and most useful services provided by AWS for collecting, analyzing and storing data in cloud, with particular attention on agility and scalability of the infrastructures.A practical session will be then focused on using Docker for emulating an AWS environment in your local laptop.
Prerequisites: Python 3+, Docker (It has to be installed, that’s enough).
#AWS #cloud #pipeline #docker #dataengineering


“Real Time Ingestion and Analysis of data with MongoDB and Python” by AXANT
Real Time Ingestion and Analysis of data with MongoDB and Python
Teacher: Alessandro Molina — AXANT
Nowadays more and more data is generated by companies and software products, especially in the IoT world records are saved with a throughput of thousands per second.
That requires solutions able to scale writes and perform real time cleanup and analysis of thousands of records per second and MongoDB is getting wildly used in those
environments in the role of what’s commonly named “speed layers” to perform fast analytics over the most recent data and adapt or cleanup incoming records.
This session aims to show how MongoDB can be used as a primary storage for your data, scaling it to thousand of records and thousand of writes per second while also acting as a real-time analysis and visualization channel thanks to change streams and as a flexible analytics tool thanks to the aggregation pipeline and MapReduce.
Prerequisites: Python, JavaScript.
#mongodb #realtime #scaling #mapreduce


“Unburdening the analysis of Earth Observation images” by WASDI
WASDI: unburdening the analysis of Earth Observation images
Teachers: Cristiano Nattero, Paolo Campanella — WASDI
Satellite Earth-Observation images are large files and complex objects: downloading them requires a delay, analyzing them takes a toll on processing capabilities, and the upload of the results can also introduce an additional lag. Batch processing of several images can be a daunting task.
WASDI (Web Advanced Space Developer Interface) is an open source web application that eases the job, by letting the users concentrate on the conceptual analysis, rather than on the infrastructural issues. This advantage is obtained by moving the processors to the data, rather than the other way around, and exploiting the computational power of the same cloud where the images are stored.
The lecture will show – hands on! – how to get existing images, how to plan the acquisition of new images, how to manipulate and elaborate them using library functions, and how to deploy your own code to run your own custom processing on the cloud.}
Prerequisites: Chrome, Python for scripting
#EOdata #Earth-Observation #datascience #WASDI #ESA
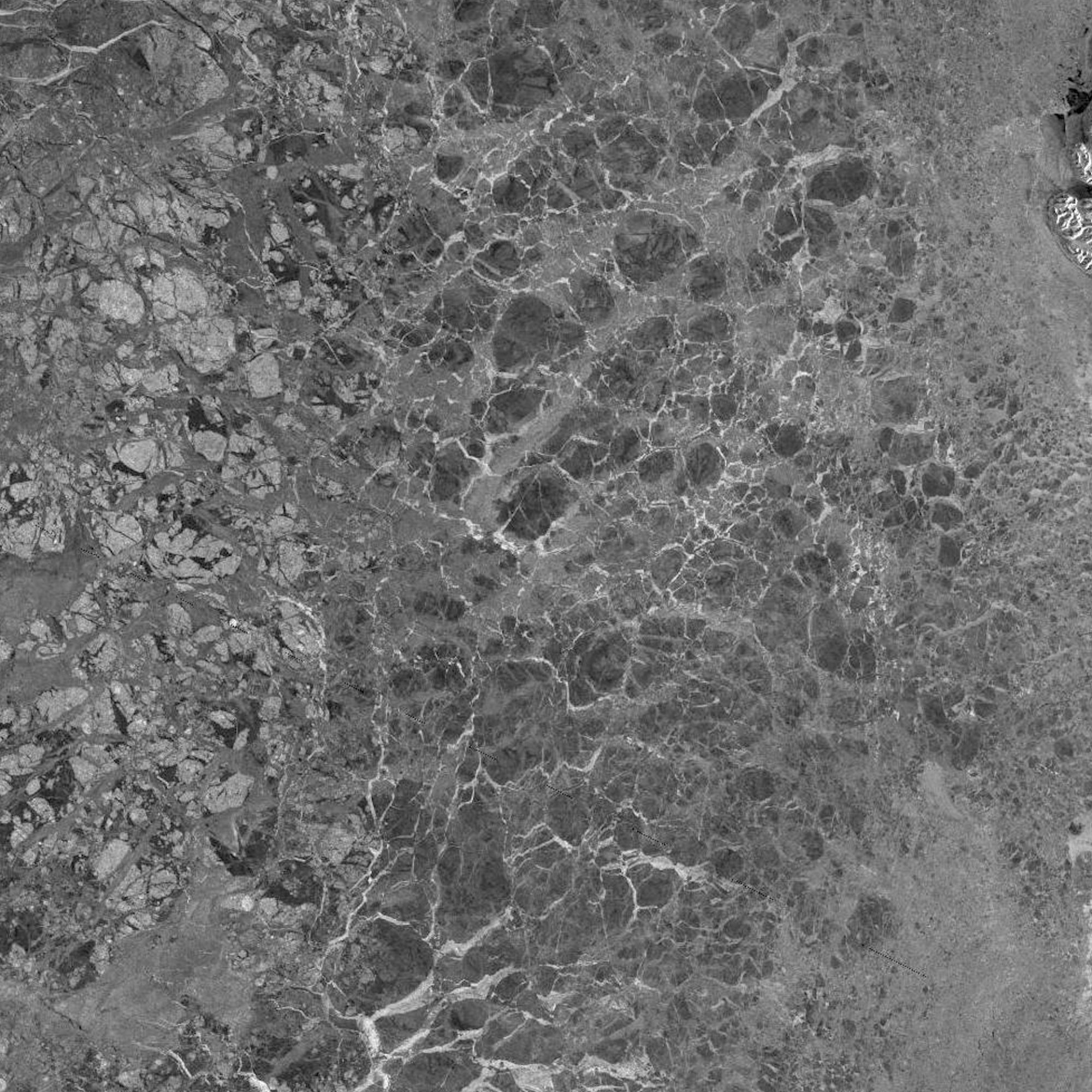
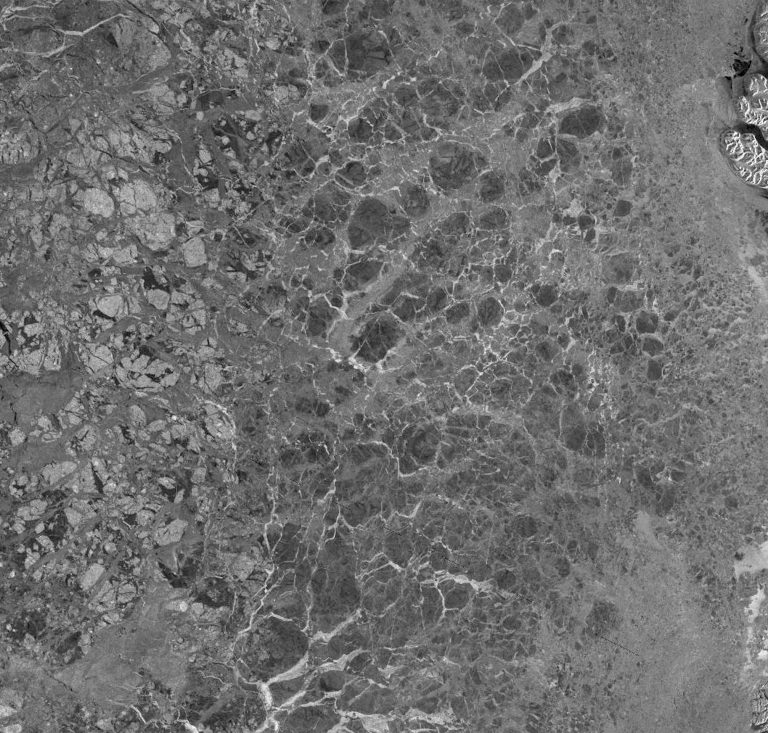
“Automating satellite-based ice charting using AI” by TUD
Automating satellite-based ice charting using AI
Speaker: Leif Toudal Pedersen — Technical University of Denmark
High resolution Synthetic Aperture Radar (SAR) satellite images are used extensively for producing sea ice charts in support for Arctic navigation. However, due to ambiguities in the relationship between C-band SAR backscatter and ice conditions (different ice types and concentrations as well as different wind conditions have the same backscatter signature) the process of producing ice charts is done by manual interpretation of the satellite data. The process is labour intensive and time consuming, and thus, the number of charts that are produced on a given day is limited.
Automatically generated high resolution sea ice maps have the potential to increase the use of satellite imagery in ice charting by providing more products and at shorter delays between acquisition and product availability.
While the 40m pixel size in Sentinel-1 data potentially enables extraction of ice information at an unprecedented high resolution, the supplementary coarser resolution AMSR2 measurements may contribute with a higher contrast between ice and water and less sensitivity to wind conditions over the ocean.
For the study a dataset of ice charts and corresponding co-located Sentinel-1 SAR and AMSR2 microwave radiometer imagery has been collected. The dataset may be split for training, testing and validation as appropriate.
Prerequisites: Data files are in NetCDF format, so you should be able to read and digest those. Basic knowledge of microwave remote sensing may be useful.
#SAR #AMSR2 #satellite #Sentinel1 #seaice


“Collaborative dataset generation for object detection on satellite imagery” by Starlab
Collaborative dataset generation for object detection on satellite imagery
Teacher: Juan B. Pedro — Starlab
Some studies suggest that most data scientists spend only 20% of their time on actual data analysis and 80% of their time finding, cleaning and reorganizing data. This inefficiency can increase even more when working with EO data, since it has a difficult access and it is very expensive to label in terms of time and human expertise. Some datasets exist today for training ML/DL models on EO data, but due to its nature, they are limited to specific tasks on very limited areas.
The POINTOUT project goal is to alleviate this problem by providing easy access to EO data and tools to perform collaborative labeling. Through a web based platform, users can annotate objects directly onto a map to build datasets that can then be downloaded and used to train learning models. We believe that tools like POINTOUT can result in massive speedup on the EO data scientist workflow.
In this session, attendees will be given the task to train an object recognition model from scratch. To that end, they will have to use the POINTOUT platform to download datasets, adding new annotations to existing ones or even creating new datasets with new labels in a collaborative way.
Prerequisites: Google Colaboratory.
#DL #ML #AI4EO #EarthObservation #Datascience
“Machine Learning and Deep Learning for Computer Vision” by ISI
Machine Learning and Deep Learning for Computer Vision
Teachers: Andrè Panisson, Alan Perotti — ISI Foundation
This in-depth part of the course allows to build an appealing and diversified Machine Learning portfolio. It starts with a Machine Learning introduction and application with Scikit-learn, and continues with Neural Networks and backpropagation lectures where you’ll start exploring Computer Vision techniques on a dataset of images.
Deep Learning methods. You’ll be challenged to use TensorFlow and Keras on a image classification real cases. The workshop ends with lessons in Transfer Learning and one last project building your data set by scraping Google images and practicing everything you learned.
Prerequisites: Python, Pandas, Statistics, exposure to Machine Learning is welcome.
#machinelearning #deeplearning #neuralnetworks #scikitlearn #tensorflow


“Advanced Deep Learning for NLP” by Harman-Samsung
Advanced Deep Learning for NLP
Teacher: Cristiano De Nobili – Harman-Samsung
This lecture is intended to be an advanced Deep Learning lecture on NLP.
In the first part, we touch some relevant concepts in NLP, such as word and character embedding. In addition, we review with the ‘eye of a physicist‘ a few Information Theory quantities which are fundamental in machine learning.
During the second part, we understand how to build a Seq2seq (encoder/decoder) algorithm and how to train it. This architecture is at the core of many state-of-the-art NLP applications, such as language translators.
Case study: we will build a spell checker which is able to correct spelling mistakes in a sentence.
This is a simple model which takes advantage of the attention mechanism. We will also devote some time to build our dataset. This exercise is also thought to be an opportunity to test and learn the latest versions of TensorFlow (1.13 and 2.0).
Prerequisites: Curiosity (a lot), Python (a bit), TensorFlow (a bit), and Deep Learning basics.
#deeplearning #NLP #tensorflow #python #machinelearning


“Let’s meet HPC4AI” by Unito
Let’s meet HPC4AI
Speaker: Marco Aldinucci — Coordinator of Turin’s competence center in HPC for Artificial Intelligence and National delegate (Italy) at the EuroHPC governing board
In this talk we’ll meet and explore the Turin’s High-Performance Centre for Artificial Intelligence.
The University of Turin and Polytechnic University of Turin have joined forces to create a federated competence centre on High-Performance Computing (HPC), Artificial Intelligence (AI) and Big Data Analytics (BDA). A centre capable to collaborate with entrepreneurs to boost their ability to innovate on data-driven technologies and applications.
The first goal of HPC4AI is to establish a large and modern laboratory to co-design with industries and SMEs research and technology transfer projects. HPC4AI has been co-funded by Regione Piemonte via EU POR-FESR 2014-2020 with 4.5M€ and will ready for service at beginning of 2019.
#HPC #HPC4AI #AI #EuroHPC


“Formalizing (and achieving?) Fairness in Machine Learning” by NEXA Center
Formalizing (and achieving?) Fairness in Machine Learning
Teacher: Antonio Vetrò — Politecnico di Torino
(Nexa Center for Internet & Society, DAUIN and Future Urban Legacy Lab)
Machine Learning techniques are a fundamental tool for automated decision systems and recommenders that substitute or support experts in a high number of decisions and fields (e.g., ranging from automated resume screening to credit score systems to criminal justice support systems).
In such a context, an increasing number of scientific studies and journalistic investigations has shown that such data-driven decision systems may have discriminating behaviors and amplify inequalities in society. In this talk we provide an overview of the problem, and we present preliminary approaches for measuring and possibly achieving fairness in ML-driven decision systems.
Prerequisites: Knowledge of R or Python, basics of probability.
#fair ML #data bias #decision systems #algorithmic discrimination


“Epidemics in Networks and Space” by MoBS Lab
Epidemics in Networks and Space
Teacher: Matteo Chinazzi — MoBS Lab, Northeastern University
Matteo Chinazzi is an Associate Research Scientist at the Laboratory for the Modeling of Biological and Socio-Technical Systems (MOBS Lab) and Part-time Faculty at Northeastern University.
This workshop will provide an introduction to the simulation of epidemic processes on complex networks embedded in a physical space.
Prerequisites: Python3.6+ and NetworkX.
#networkscience #networkx #epidemiology